基本介绍
独立硬盘冗余阵列(RAID, Redundant Array of Independent Disks),旧称廉价磁盘冗余阵列(Redundant Array of Inexpensive Disks),简称磁盘阵列。利用虚拟化存储技术把多个硬盘组合起来,成为一个或多个硬盘阵列组,目的为提升性能或减少冗余,或是两者同时提升。
在运作中,取决于 RAID 层级不同,资料会以多种模式分散于各个硬盘,RAID 层级的命名会以 RAID 开头并带数字,例如:RAID 0、RAID 1、RAID 5、RAID 6、RAID 7、RAID 01、RAID 10、RAID 50、RAID 60。每种等级都有其理论上的优缺点,不同的等级在两个目标间获取平衡,分别是增加资料可靠性以及增加存储器(群)读写性能。
| RAID |
最少硬盘 |
最大容错 |
可用容量 |
读取性能 |
写入性能 |
安全性 |
目的 |
应用 |
| UNRAID |
1 |
0 |
1 |
1 |
1 |
无 |
|
到处都有 |
| JBOD |
1 |
0 |
n |
1 |
1 |
无 |
单纯增加容量 |
个人 |
| 0 |
2 |
0 |
n |
n |
n |
一个硬盘寄了就全寄了 |
追求快 |
缓存 |
| 1 |
2 |
n-1 |
1 |
n |
1 |
高,一块硬盘正常即可 |
追求稳 |
个人、企业备份 |
| 5 |
3 |
1 |
n-1 |
n-1 |
n-1 |
低,不能坏超过一块 |
追求快稳便宜 |
个人、小型企业备份 |
| 6 |
4 |
2 |
n-2 |
n-2 |
n-2 |
比RAID5高,不能坏超过两块 |
追求快加更稳 |
个人、企业备份 |
| 10 |
4 |
|
|
|
|
|
又稳又快 |
大型数据库、服务器 |
| 50 |
6 |
|
|
|
|
|
又稳又快但起步价小贵 |
|
| 60 |
8 |
|
|
|
|
|
又稳又快但起步价贵 |
|
- n 代表硬盘总数
- JBOD(Just a Bunch Of Disk) 指将数个物理硬盘,在操作系统中合并成一个逻辑硬盘,直接增加容量
- 10、50、60、依照组成公式不同,容量和性能也不同
RAID 0

RAID 0 亦称为带区集。它将两个以上的磁盘并联起来,成为一个大容量的磁盘。在存放数据时,分段后分散存储在这些磁盘中,因为读写时都可以并行处理,所以在所有的级别中,RAID 0 的速度是最快的。但是 RAID 0 既没有冗余功能,也不具备容错能力,如果一个磁盘(物理)损坏,所有数据都会丢失,危险程度与JBOD相当。
RAID 1
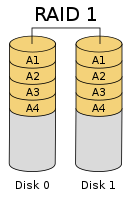
两组以上的 N 个磁盘相互作镜像,在一些多线程操作系统中能有很好的读取速度,理论上读取速度等于硬盘数量的倍数,与 RAID 0 相同。另外写入速度有微小的降低。只要一个磁盘正常即可维持运作,可靠性最高。其原理为在主硬盘上存放数据的同时也在镜像硬盘上写一样的数据。当主硬盘(物理)损坏时,镜像硬盘则代替主硬盘的工作。因为有镜像硬盘做数据备份,所以 RAID 1 的数据安全性在所有的 RAID 级别上来说是最好的。但无论用多少磁盘做 RAID 1,仅算一个磁盘的容量,是所有 RAID 中磁盘利用率最低的一个级别。
如果用两个不同大小的磁盘建 RAID 1,可用空间为较小的那个磁盘,较大的磁盘多出来的空间也可以分割成一个区来使用,不会造成浪费。

RAID 1 没有校验机制。如果用两个磁盘组成 RAID 1 阵列,如果两个硬盘上的数据不知怎么的变得不一致,RAID 1 不知道应该相信哪一个硬盘,这就是大脑分裂的情况。事实上,RAID 1 的磁盘数量越多,越有可能其中某个磁盘的数据变得不一致(但仍然工作),RAID 1 只会从第一个工作的硬盘里提供数据,没有办法检测到底哪个硬盘的数据不对。
RAID1:发生 bit 反转才会寄,一般机械硬盘平均每读写 10^15 个比特才有可能反转一个 bit,否则只要有一块硬盘正常,就可以恢复数据
RAID 5

RAID Level 5 是一种储存性能、数据安全和存储成本兼顾的存储解决方案。它使用的是 Disk Striping(硬盘分割)技术。
RAID 5 至少需要三个硬盘,RAID 5 不是对存储的数据进行备份,而是把数据和相对应的奇偶校验信息存储到组成 RAID 5 的各个磁盘上,并且奇偶校验信息和相对应的数据分别存储于不同的磁盘上。当 RAID 5 的一个磁盘数据发生损坏后,可以利用剩下的数据和相应的奇偶校验信息去恢复被损坏的数据。RAID 5 可以理解为是 RAID 0 和 RAID 1 的折衷方案。RAID 5 可以为系统提供数据安全保障,但保障程度要比镜像低而磁盘空间利用率要比镜像高。RAID 5 具有和 RAID 0 相近似的数据读取速度,只是因为多了一个奇偶校验信息,
写入数据的速度相对单独写入一块硬盘的速度略慢,若使用“回写缓存”可以让性能改善不少。同时由于多个数据对应一个奇偶校验信息,RAID 5 的磁盘空间利用率要比 RAID 1 高,存储成本相对较便宜。
RAID 6
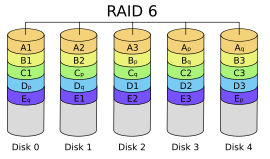
与 RAID 5 相比,RAID 6 增加第二个独立的奇偶校验信息块。两个独立的奇偶系统使用不同的算法,数据的可靠性非常高,任意两块磁盘同时失效时不会影响数据完整性。RAID 6 需要分配给奇偶校验信息更大的磁盘空间和额外的校验计算,相对于 RAID 5 有更大的 IO 操作量和计算量,其“写性能”强烈取决于具体的实现方案,因此 RAID 6 通常不会通过软件方式来实现,而更可能通过硬件方式实现。
同一数组中最多容许两个磁盘损坏。更换新磁盘后,资料将会重新算出并写入新的磁盘中。
依照设计理论,RAID 6 必须具备四个以上的磁盘才能生效。可使用的容量为硬盘总数减去 2 的差,乘以最小容量,公式为:
同理,数据保护区域容量则为最小容量乘以 2。
RAID 6 在硬件磁盘阵列卡的功能中,也是最常见的磁盘阵列等级。
实现
Storage Networking Industry Association (SNIA) 对于 RAID 6 的定义是:”在任意两块磁盘同时失效的情况下,仍然能够对RAID中的所有虚拟磁盘执行读写操作的RAID实现。迄今已经有:奇偶 和 里德-所罗门 双校验、正交双奇偶校验和对角奇偶校验等若干方法用于实现 RAID 6。”
为了达到容忍任意两块磁盘失效的目的,需要计算两种不同的综合解码。其中之一是 P,可以像 RAID 5 那样经过简单的异或计算获得,而另一个不同的综合编码则比较复杂,需要利用[域论]来解决。
反正就非常复杂
软件方式实现的 RAID 6 对于系统性能会有明显的影响,而硬件方案则相对复杂。
RAID 10/01


RAID 10 是先分割资料再镜像,再将所有硬盘分为两组,视为以 RAID 1 作为最低组合,然后将每组 RAID 1 视为一个“硬盘”组合为 RAID 0 运作。
RAID 01 则是跟 RAID 10 的程序相反,是先镜像再将资料到分割两组硬盘。它将所有的硬盘分为两组,每组各自构成为 RAID 0 作为最低组合,而将两组硬盘组合为 RAID 1 运作。
当 RAID 10 有一个硬盘受损,其余硬盘会继续运作。RAID 01 只要有一个硬盘受损,同组 RAID 0 的所有硬盘都会停止运作,只剩下其他组的硬盘运作,可靠性较低。如果以六个硬盘建 RAID 01,镜像再用三个建 RAID 0,那么坏一个硬盘便会有三个硬盘离线。因此,RAID 10 远较 RAID 01 常用,零售主板绝大部分支持RAID 0/1/5/10,但不支持 RAID 01。
RAID 50

RAID 5 与 RAID 0 的组合,先作 RAID 5,再作 RAID 0,也就是对多组 RAID 5 彼此构成 Stripe 访问。由于 RAID 50 是以 RAID 5 为基础,而 RAID 5 至少需要 3 颗硬盘,因此要以多组 RAID 5 构成 RAID 50,至少需要 6 颗硬盘。以 RAID 50 最小的 6 颗硬盘配置为例,先把 6 颗硬盘分为 2 组,每组 3 颗构成 RAID 5,如此就得到两组 RAID 5,然后再把两组 RAID 5 构成 RAID 0。
RAID 50 在底层的任一组或多组 RAID 5 中出现 1 颗硬盘损坏时,仍能维持运作,不过如果任一组 RAID 5 中出现 2 颗或 2 颗以上硬盘损毁,整组 RAID 50 就会失效。
RAID 50 由于在上层把多组 RAID 5 构成 Stripe,性能比起单纯的 RAID 5 高,容量利用率比 RAID5 要低。比如同样使用 9 颗硬盘,由各 3 颗 RAID 5 再组成 RAID 0 的 RAID 50,每组 RAID 5 浪费一颗硬盘,利用率为 (1-3/9),RAID 5 则为 (1-1/9)。
RAID 60

RAID 6 与 RAID 0 的组合:先作 RAID 6,再作 RAID 0。换句话说,就是对两组以上的 RAID 6 作 Stripe 访问。RAID 6 至少需具备 4 颗硬盘,所以 RAID 60 的最小需求是 8 颗硬盘。
由于底层是以 RAID 6 组成,所以 RAID 60 可以容许任一组 RAID 6 中损毁最多 2 颗硬盘,而系统仍能维持运作;不过只要底层任一组 RAID 6 中损毁 3 颗硬盘,整组 RAID 60 就会失效,当然这种情况的概率相当低。
比起单纯的 RAID 6,RAID 60 的上层透过结合多组 RAID 6 构成 Stripe 访问,因此性能较高。不过使用门槛高,而且容量利用率低是较大的问题。
由八块相同硬盘组成 RAID 60 的话,每组 RAID6 使用两块硬盘来存奇偶校验信息,硬盘利用率是 50%

















